KubeEdge在国家工业互联网大数据中心的架构设计与应用 驱动互联网数据服务新范式
引言:融合边缘与云,重塑工业数据服务
随着工业互联网的深入发展,国家工业互联网大数据中心承载着汇聚、处理与分析海量工业数据,赋能产业升级与创新的核心使命。传统以中心云为核心的架构在处理工业现场实时性、低延迟、高带宽消耗和数据隐私安全等需求时面临挑战。KubeEdge,作为业界首个云原生边缘计算开源项目,凭借其云边协同、边缘自治、应用与设备管理一体化等特性,为构建新一代工业互联网数据服务体系提供了理想的底层架构支撑。
一、 核心架构设计:云边端一体化协同
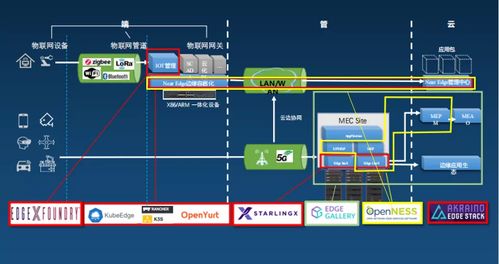
在国家工业互联网大数据中心的整体蓝图中,KubeEdge的架构设计旨在实现“中心云-边缘节点-现场设备”三层高效协同。
- 云端核心(CloudCore):部署于大数据中心的云基础设施中,作为控制面大脑。它负责边缘节点的生命周期管理、应用下发、策略配置以及来自全网边缘数据的汇聚、存储与全局分析。通过与中心已有的容器编排平台(如Kubernetes)无缝集成,实现了对边缘应用与中心云应用的统一编排与管理。
- 边缘节点(EdgeNode):部署在靠近工业现场的数据中心分中心、园区或工厂内部。每个边缘节点运行轻量化的KubeEdge组件,负责接收并执行来自云端的指令,管理本地的容器化应用。更重要的是,它具备边缘自治能力,在网络不稳定或与云端断开时,能独立保证关键业务的持续运行。
- 设备层集成:通过KubeEdge的设备孪生(Device Twin)和Mapper框架,将各类工业协议(如OPC UA、Modbus)的设备抽象为标准化的数字模型,纳入统一的云原生管理体系。这使得海量异构工业设备的数据能够被高效、安全地采集并上报至边缘节点或云端。
二、 在互联网数据服务中的关键应用场景
基于上述架构,KubeEdge在国家工业互联网大数据中心的数据服务体系中发挥着关键作用:
- 实时数据预处理与边缘洞察:工业现场产生的原始数据(如传感器时序数据、视频流)体量巨大且蕴含大量噪声。在边缘节点部署轻量化的数据清洗、过滤、聚合和特征提取应用,可以实现“数据不出园区/工厂”,在源头完成预处理。仅将高价值、低带宽的摘要数据或异常事件上报至中心云,极大降低了网络带宽压力和云端处理负载,同时满足了实时监控与快速响应的需求。
- 低延迟智能分析与控制闭环:对于要求毫秒级响应的应用(如设备预测性维护、工艺参数实时优化、AGV调度),将AI推理模型或规则引擎下沉至边缘节点。数据在本地完成分析,并直接驱动现场控制指令的下发,形成快速的控制闭环,避免了因数据往返云端带来的延迟,显著提升了生产效率和安全性。
- 数据安全与隐私保护:工业数据涉及核心工艺和商业秘密。KubeEdge架构支持敏感数据在边缘侧完成处理和分析,只有脱敏后的结果或模型参数(如联邦学习场景)与云端交互。这种模式从架构层面强化了数据主权和隐私保护,符合国家工业数据安全管理要求。
- 规模化、统一的应用与设备管理:大数据中心需要管理成千上万的边缘节点和设备。KubeEdge提供了与Kubernetes一致的应用声明式部署和管理体验,实现了从中心云到全国范围内部署的边缘应用“一键下发、统一运维”。设备孪生技术使得设备状态在云端实时可视,远程诊断和配置更新成为可能,大幅降低了运维成本。
- 异构资源纳管与生态构建:国家工业互联网连接着从高端数控机床到普通传感器的海量异构资源。KubeEdge的开放框架能够兼容X86、ARM等多种硬件架构和不同的边缘运行时环境,为整合各类工业软硬件资源、构建繁荣的应用生态提供了统一的技术底座。
三、 实践价值与未来展望
将KubeEdge应用于国家工业互联网大数据中心架构,其核心价值在于:
- 降本增效:减少不必要的数据上云,节约带宽与云存储成本;边缘智能提升业务响应效率。
- 增强可靠性:边缘自治保障了关键业务在复杂网络环境下的高可用性。
- 加速创新:云原生的统一平台加速了工业AI应用、数字孪生等创新服务的开发、测试与规模化部署。
随着5G、确定性网络与KubeEdge的进一步融合,工业互联网数据服务的实时性与确定性将得到更强保障。边缘侧算力的不断增强,将推动更加复杂的协同智能(如跨边缘节点的分布式推理与学习)成为可能,使国家工业互联网大数据中心真正成为一个“云边端”智能协同、数据价值全域流动的神经中枢,为制造业高质量发展提供源源不断的数字化动力。
如若转载,请注明出处:http://www.zbtljju.com/product/60.html
更新时间:2026-06-19 08:14:23